
Faster inference, longer battery life, and less storage on edge devices
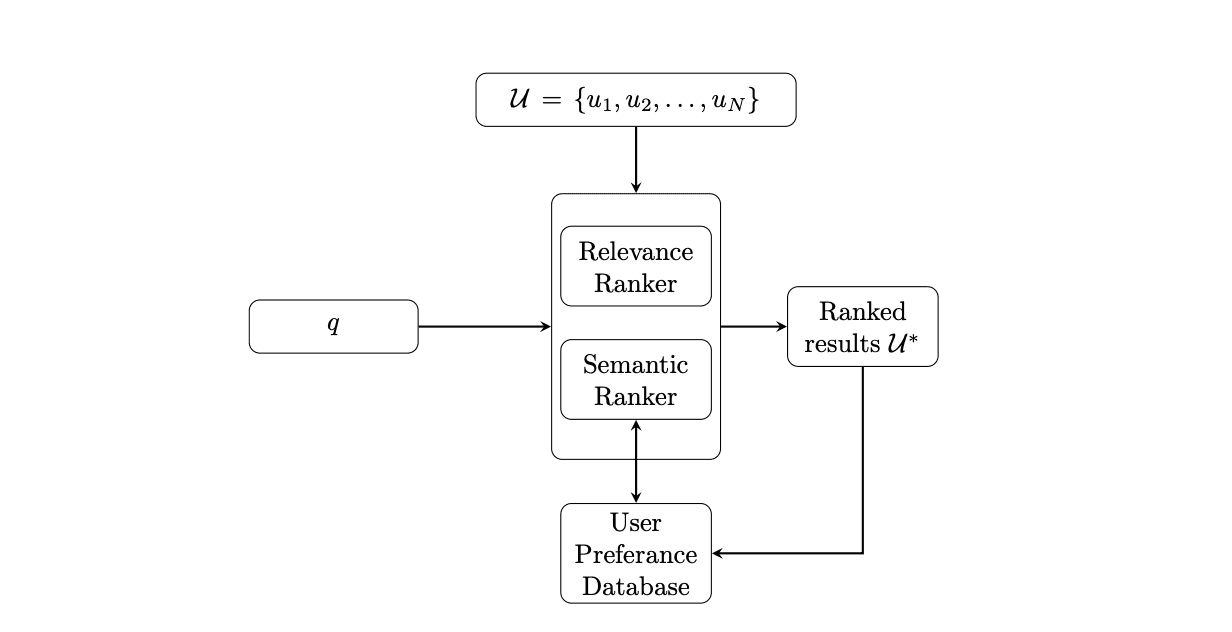
Modern search systems use several large ranker models with transformer architectures. These models require large computational resources and are not suitable for usage on devices with limited computational resources. Knowledge distillation is a popular compression technique that can reduce resource needs of such models, where a large teacher model transfers knowledge to a small student model. To drastically reduce memory requirements and energy consumption, we propose two extensions for a popular sentence-transformer distillation procedure: generation of an optimal size vocabulary and dimensionality reduction of the embedding dimension of teachers prior to distillation. We evaluate these extensions on two different types of ranker models. This results in extremely compressed student models whose analysis on a test dataset shows the significance and utility of our proposed extensions.
Read the entire research paper here.










" width="149.49200000000002px"><path d="M 106.382 88.383 L 25.113 88.383 L 25.113 87.17 L 49.135 87.17 C 44.783 85.814 43.901 82.035 44.172 77.858 L 50.508 77.858 C 50.508 80.746 50.631 83.176 54.122 83.176 C 56.262 83.176 57.309 81.799 57.309 79.742 C 57.309 74.295 44.546 73.954 44.546 64.955 C 44.546 60.221 46.811 56.448 54.543 56.448 C 60.711 56.448 63.778 59.212 63.358 65.538 L 57.188 65.538 C 57.188 63.275 56.809 60.975 54.246 60.975 C 52.19 60.975 50.971 62.105 50.971 64.197 C 50.971 69.941 63.737 69.436 63.737 78.948 C 63.737 84.162 61.187 86.317 58.058 87.17 L 71.632 87.17 C 65.801 85.697 65.014 81.042 65.014 71.824 C 65.014 64.197 65.396 56.448 75.763 56.448 C 81.978 56.448 85.838 59.925 85.464 66.251 L 79.164 66.251 C 79.209 63.442 78.746 60.975 75.384 60.975 C 71.438 60.975 71.438 66.296 71.438 72.16 C 71.438 81.622 72.365 83.302 75.973 83.302 C 77.024 83.302 78.159 83.049 79.121 82.715 L 79.121 76.014 L 75.681 76.014 L 75.681 71.361 L 85.464 71.361 L 85.464 86.695 C 84.807 86.825 83.777 87.002 82.61 87.17 L 92.037 87.17 C 87.681 85.814 86.803 82.035 87.068 77.858 L 93.406 77.858 C 93.406 80.746 93.533 83.176 97.023 83.176 C 99.158 83.176 100.21 81.799 100.21 79.742 C 100.21 74.295 87.444 73.954 87.444 64.955 C 87.444 60.221 89.712 56.466 97.44 56.448 C 102.815 56.437 105.823 58.474 106.382 63.036 L 106.382 50.88 L 107.596 50.88 L 107.596 87.17 L 118.884 87.17 L 118.884 88.383 L 107.596 88.383 L 107.596 94.635 L 106.382 94.635 Z M 100.96 87.17 L 106.382 87.17 L 106.382 81.56 C 105.664 84.921 103.505 86.471 100.96 87.17 Z M 106.382 65.538 L 100.255 65.538 C 100.259 63.336 99.705 60.975 97.146 60.975 C 95.086 60.975 93.867 62.105 93.867 64.197 C 93.867 69.459 104.589 69.481 106.382 76.759 Z M 98.523 121.845 L 111.908 121.845 L 111.908 127.911 L 108.039 127.911 L 108.039 149.035 L 102.441 149.035 L 102.443 127.9 L 98.523 127.9 Z M 143.107 116.204 L 148.63 116.204 L 140.09 149.035 L 133.532 149.035 L 128.677 129.08 L 134.265 129.08 L 136.903 141.629 L 136.979 141.629 Z M 119.225 127.911 L 113.099 127.911 L 113.099 121.85 L 119.225 121.85 Z M 127.472 127.911 L 121.344 127.911 L 121.344 121.85 L 127.472 121.85 Z M 121.353 129.102 L 127.477 129.102 L 127.466 149.031 L 117.361 149.031 C 117.334 149.031 117.305 149.028 117.276 149.028 C 114.961 149.028 113.096 147.135 113.096 144.791 C 113.096 144.736 113.092 144.686 113.096 144.633 C 113.084 138.314 113.096 129.102 113.096 129.102 L 119.235 129.102 L 119.181 142.102 C 119.181 142.102 119.181 142.128 119.185 142.165 C 119.185 142.176 119.181 142.188 119.181 142.206 C 119.181 142.528 119.339 142.811 119.584 142.98 C 119.617 143.006 119.658 143.024 119.7 143.047 C 119.73 143.06 119.759 143.073 119.793 143.082 C 119.831 143.097 119.868 143.113 119.913 143.124 C 119.973 143.137 120.042 143.143 120.108 143.143 C 120.118 143.143 120.125 143.143 120.138 143.138 C 120.164 143.138 120.185 143.149 120.211 143.146 C 120.266 143.143 121.353 143.146 121.353 143.146 Z M 105.023 160.856 C 102.659 160.856 102.218 159.465 102.318 157.888 L 104.229 157.888 C 104.229 158.757 104.263 159.49 105.314 159.49 C 105.958 159.49 106.275 159.075 106.275 158.456 C 106.275 156.809 102.432 156.711 102.432 153.995 C 102.432 152.566 103.116 151.426 105.44 151.426 C 107.298 151.426 108.222 152.262 108.094 154.172 L 106.239 154.172 C 106.239 153.489 106.124 152.792 105.35 152.792 C 104.733 152.792 104.366 153.134 104.366 153.766 C 104.366 155.498 108.208 155.346 108.208 158.214 C 108.208 160.58 106.477 160.856 105.023 160.856 Z M 112.192 160.706 L 114.718 151.579 L 117.235 151.579 L 119.711 160.706 L 117.701 160.706 L 117.196 158.681 L 114.592 158.681 L 114.074 160.706 Z M 115.87 153.338 L 115.844 153.338 L 114.972 157.281 L 116.791 157.281 Z M 122.884 160.706 L 125.415 151.579 L 127.931 151.579 L 130.406 160.706 L 128.398 160.706 L 127.892 158.681 L 125.29 158.681 L 124.769 160.706 Z M 126.564 153.338 L 126.54 153.338 L 125.666 157.281 L 127.486 157.281 Z M 136.331 160.706 L 134.421 160.706 L 134.421 151.579 L 137.946 151.579 C 139.248 151.579 140.082 152.412 140.082 153.969 C 140.082 155.131 139.627 156.006 138.389 156.207 L 138.389 156.23 C 138.806 156.282 140.045 156.382 140.045 158.026 C 140.045 158.609 140.082 160.326 140.259 160.706 L 138.389 160.706 C 138.137 160.15 138.186 159.53 138.186 158.936 C 138.186 157.847 138.289 156.926 136.823 156.926 L 136.331 156.926 Z M 136.331 155.522 L 137.175 155.522 C 137.934 155.522 138.148 154.765 138.148 154.184 C 138.148 153.311 137.782 152.983 137.175 152.983 L 136.331 152.983 Z M 149.492 112.121 L 134.543 112.121 L 134.543 74.747 C 134.543 41.721 107.771 14.946 74.744 14.946 C 41.72 14.946 14.948 41.721 14.948 74.747 C 14.948 74.798 0 74.798 0 74.747 C 0 33.466 33.463 0 74.744 0 C 116.027 0 149.492 33.465 149.492 74.747 Z M 32.611 17.399 L 33.658 21.372 L 30.136 19.295 L 29.249 19.976 L 33.874 22.547 L 35.691 24.919 L 36.484 24.311 L 34.668 21.94 L 33.413 16.784 Z M 48.74 17.06 L 52.542 15.497 L 52.211 14.693 L 49.335 15.876 L 48.301 13.366 L 50.915 12.291 L 50.585 11.487 L 47.97 12.563 L 47.011 10.234 L 49.826 9.076 L 49.496 8.273 L 45.755 9.811 Z M 54.573 14.769 L 52.663 8.069 L 52.684 8.062 L 56.664 14.174 L 57.573 13.915 L 57.774 6.613 L 57.795 6.607 L 59.706 13.308 L 60.667 13.034 L 58.519 5.499 L 56.93 5.951 L 56.81 12.823 L 56.789 12.829 L 53.084 7.046 L 51.526 7.489 L 53.674 15.025 Z M 44.294 10.453 L 39.734 12.794 L 40.131 13.567 L 41.966 12.625 L 45.15 18.825 L 46.039 18.369 L 42.855 12.168 L 44.69 11.226 Z M 29.198 27.444 L 28.472 28.115 C 28.963 28.68 30.162 29.981 31.847 28.396 C 32.797 27.519 33.274 26.354 32.157 25.141 C 30.473 23.313 28.056 25.884 26.887 24.615 C 26.313 23.993 26.554 23.357 26.993 22.952 C 27.687 22.31 28.269 22.541 28.842 23.179 L 29.608 22.471 C 28.575 21.254 27.514 21.289 26.46 22.261 C 25.495 23.153 25.269 24.367 26.21 25.388 C 27.806 27.12 30.259 24.588 31.436 25.865 C 32.068 26.551 31.85 27.212 31.267 27.75 C 30.796 28.185 30.073 28.394 29.353 27.612 Z M 89.75 13.29 L 90.716 13.545 L 91.628 10.081 L 94.273 10.78 L 94.494 9.941 L 91.849 9.241 L 92.489 6.805 L 95.281 7.544 L 95.503 6.704 L 91.744 5.71 Z M 128.765 28.145 L 128.159 27.493 L 123.246 32.067 L 123.231 32.051 L 126.064 25.243 L 125.102 24.21 L 119.363 29.553 L 119.969 30.205 L 124.946 25.572 L 124.96 25.588 L 122.093 32.486 L 123.026 33.488 Z M 112.997 24.162 L 117.646 17.849 L 116.84 17.257 L 112.191 23.569 Z M 76.957 7.995 L 78.129 8.051 C 78.466 8.067 79.233 8.147 79.264 9.106 C 79.301 10.151 79.187 11.168 79.443 11.724 L 80.484 11.774 C 80.356 11.278 80.307 10.047 80.312 9.71 C 80.332 8.134 80.022 7.815 79.128 7.631 L 79.129 7.61 C 80.059 7.491 80.603 6.81 80.647 5.888 C 80.693 4.911 80.252 3.912 78.863 3.845 L 76.161 3.716 L 75.787 11.549 L 76.785 11.597 Z M 76.999 7.127 L 77.118 4.631 L 78.626 4.704 C 79.397 4.74 79.648 5.383 79.621 5.947 C 79.589 6.631 79.212 7.233 78.496 7.198 Z M 116.271 23.008 C 114.855 24.656 114.905 25.831 116.166 26.915 C 117.426 27.998 118.595 27.871 120.011 26.223 L 121.69 24.27 C 122.709 23.084 122.75 21.801 121.49 20.718 C 120.229 19.635 118.968 19.869 117.949 21.056 Z M 119.209 25.59 C 118.09 26.892 117.428 26.896 116.711 26.28 C 115.995 25.664 115.898 25.009 117.017 23.707 L 118.745 21.696 C 119.813 20.452 120.706 21.148 120.945 21.353 C 121.184 21.558 122.005 22.336 120.936 23.58 Z M 95.445 14.942 L 97.902 7.495 L 96.953 7.182 L 94.497 14.629 Z M 70.467 11.697 L 74.568 11.542 L 74.535 10.673 L 71.432 10.792 L 71.329 8.079 L 74.15 7.972 L 74.117 7.104 L 71.296 7.211 L 71.201 4.694 L 74.238 4.579 L 74.206 3.711 L 70.17 3.864 Z M 115.573 16.3 L 111.251 13.542 L 110.784 14.275 L 112.524 15.385 L 108.772 21.263 L 109.614 21.8 L 113.366 15.922 L 115.105 17.033 Z M 38.317 20.142 L 37.481 20.671 C 37.863 21.316 38.808 22.811 40.753 21.554 C 41.846 20.862 42.526 19.802 41.645 18.408 C 40.317 16.308 37.475 18.403 36.553 16.945 C 36.1 16.23 36.452 15.647 36.958 15.327 C 37.757 14.821 38.288 15.153 38.737 15.883 L 39.619 15.325 C 38.821 13.942 37.771 13.786 36.558 14.553 C 35.446 15.256 35.005 16.409 35.747 17.583 C 37.005 19.573 39.877 17.525 40.805 18.991 C 41.304 19.78 40.969 20.39 40.298 20.815 C 39.756 21.157 39.007 21.234 38.439 20.335 Z M 102.472 11.546 L 103.427 11.936 C 104.092 10.565 103.843 9.595 102.405 9.008 C 100.977 8.425 99.834 8.639 98.996 10.691 L 98.159 12.742 C 97.01 15.557 98.373 16.184 99.278 16.553 C 99.751 16.746 101.37 17.407 102.265 15.098 L 101.31 14.708 C 100.721 16.122 99.825 15.874 99.544 15.758 C 98.83 15.467 98.333 15.018 99.06 13.238 L 99.852 11.297 C 100.361 10.05 100.616 9.944 100.679 9.875 C 100.75 9.787 101.241 9.447 102.004 9.759 C 102.196 9.838 102.595 10.094 102.692 10.404 C 102.789 10.713 102.651 11.138 102.472 11.546 Z M 67.293 6.287 L 68.316 6.157 C 68.223 4.637 67.53 3.915 65.99 4.109 C 64.46 4.302 63.569 5.049 63.846 7.246 L 64.124 9.444 C 64.504 12.461 65.999 12.338 66.968 12.215 C 67.474 12.151 69.209 11.933 68.856 9.482 L 67.833 9.611 C 68.013 11.131 67.111 11.355 66.81 11.393 C 66.045 11.489 65.392 11.341 65.151 9.435 L 64.889 7.356 C 64.721 6.02 64.89 5.801 64.912 5.711 C 64.93 5.599 65.191 5.063 66.01 4.96 C 66.214 4.934 66.689 4.962 66.924 5.184 C 67.16 5.406 67.248 5.843 67.293 6.287 Z M 107.843 11.711 L 101.977 17.477 L 102.87 17.949 L 104.261 16.573 L 106.939 17.99 L 106.565 19.905 L 107.553 20.429 L 108.966 12.305 Z M 107.949 12.811 L 107.106 17.096 L 104.889 15.922 L 107.929 12.801 Z M 87.124 4.733 L 82.039 4.048 L 81.924 4.909 L 83.971 5.185 L 83.04 12.091 L 84.03 12.224 L 84.961 5.318 L 87.008 5.593 Z M 88.083 12.937 L 89.626 5.247 L 88.646 5.05 L 87.104 12.74 Z M 0.394 83.056 L 0.247 81.609 L 11.605 80.452 L 11.752 81.899 Z M 4.384 87.154 L 4.059 87.218 C 2.538 87.516 2.245 88.572 2.424 89.487 C 2.646 90.62 3.297 91.396 4.631 91.134 C 7.114 90.649 5.851 85.675 9.219 85.017 C 11.205 84.628 12.537 85.833 12.904 87.711 C 13.305 89.759 12.536 91.102 10.237 91.455 L 9.945 89.966 C 11.174 89.741 11.905 89.195 11.641 87.845 C 11.474 86.991 10.87 86.208 9.659 86.444 C 7.192 86.928 8.533 91.886 4.979 92.581 C 2.62 93.042 1.541 91.562 1.18 89.715 C 0.502 86.416 3.031 85.921 4.108 85.742 Z M 6.887 95.067 L 10.449 93.903 C 12.614 93.195 14.36 93.856 15.112 96.155 C 15.863 98.455 14.844 100.018 12.68 100.726 L 9.118 101.89 C 6.112 102.874 4.561 102.149 3.809 99.85 C 3.058 97.551 3.881 96.05 6.887 95.067 Z M 8.596 100.498 L 12.263 99.299 C 14.533 98.557 14.097 96.97 13.955 96.533 C 13.812 96.098 13.226 94.559 10.956 95.301 L 7.289 96.5 C 4.914 97.276 4.539 98.164 4.967 99.472 C 5.394 100.779 6.221 101.274 8.596 100.498 Z M 15.549 112.358 C 13.024 113.706 10.549 115.045 9.149 112.423 C 8.375 110.972 8.852 109.481 10.4 108.69 L 11.085 109.973 C 10.374 110.353 9.784 111.027 10.223 111.849 C 10.886 113.09 12.297 112.445 14.78 111.119 L 14.765 111.091 C 13.932 111.142 13.367 110.655 12.972 109.916 C 12.563 109.149 12.193 107.482 14.843 106.067 C 17.019 104.906 18.506 105.778 19.191 107.061 C 20.606 109.712 18.157 110.965 15.549 112.358 Z M 15.556 107.336 C 14.593 107.849 13.644 108.589 14.24 109.705 C 14.835 110.821 15.979 110.443 16.94 109.929 C 17.819 109.461 18.845 108.662 18.256 107.56 C 17.668 106.459 16.434 106.867 15.556 107.336 Z M 19.923 118.845 C 17.572 120.48 15.27 122.101 13.572 119.66 C 11.874 117.218 14.194 115.624 16.544 113.989 C 18.973 112.299 21.205 110.689 22.921 113.156 C 24.638 115.623 22.351 117.156 19.923 118.845 Z M 17.142 115.345 C 15.623 116.403 13.65 117.639 14.572 118.964 C 15.493 120.289 17.339 118.87 18.858 117.813 C 21.286 116.124 22.771 115.072 21.921 113.851 C 21.072 112.631 19.57 113.657 17.142 115.345 Z M 25.051 124.728 C 22.921 126.641 20.838 128.536 18.85 126.324 C 16.862 124.112 18.966 122.242 21.096 120.328 C 23.296 118.35 25.311 116.475 27.32 118.711 C 29.329 120.946 27.251 122.751 25.051 124.728 Z M 21.857 121.6 C 20.481 122.838 18.677 124.31 19.756 125.509 C 20.834 126.71 22.49 125.073 23.866 123.836 C 26.066 121.858 27.408 120.631 26.415 119.525 C 25.42 118.419 24.057 119.623 21.857 121.6 Z M 25.869 132.788 L 24.769 131.836 L 30.903 124.742 L 28.935 124.504 L 29.845 123.451 C 30.224 123.569 31.531 123.654 32.104 123.668 L 33.049 124.485 Z" fill="rgb(255, 255, 255)" height="160.85599487304688px" id="iaZdQXHhe" width="149.49200000000002px"/></g></svg>)


" width="149.49200000000002px"><path d="M 106.382 88.383 L 25.113 88.383 L 25.113 87.17 L 49.135 87.17 C 44.783 85.814 43.901 82.035 44.172 77.858 L 50.508 77.858 C 50.508 80.746 50.631 83.176 54.122 83.176 C 56.262 83.176 57.309 81.799 57.309 79.742 C 57.309 74.295 44.546 73.954 44.546 64.955 C 44.546 60.221 46.811 56.448 54.543 56.448 C 60.711 56.448 63.778 59.212 63.358 65.538 L 57.188 65.538 C 57.188 63.275 56.809 60.975 54.246 60.975 C 52.19 60.975 50.971 62.105 50.971 64.197 C 50.971 69.941 63.737 69.436 63.737 78.948 C 63.737 84.162 61.187 86.317 58.058 87.17 L 71.632 87.17 C 65.801 85.697 65.014 81.042 65.014 71.824 C 65.014 64.197 65.396 56.448 75.763 56.448 C 81.978 56.448 85.838 59.925 85.464 66.251 L 79.164 66.251 C 79.209 63.442 78.746 60.975 75.384 60.975 C 71.438 60.975 71.438 66.296 71.438 72.16 C 71.438 81.622 72.365 83.302 75.973 83.302 C 77.024 83.302 78.159 83.049 79.121 82.715 L 79.121 76.014 L 75.681 76.014 L 75.681 71.361 L 85.464 71.361 L 85.464 86.695 C 84.807 86.825 83.777 87.002 82.61 87.17 L 92.037 87.17 C 87.681 85.814 86.803 82.035 87.068 77.858 L 93.406 77.858 C 93.406 80.746 93.533 83.176 97.023 83.176 C 99.158 83.176 100.21 81.799 100.21 79.742 C 100.21 74.295 87.444 73.954 87.444 64.955 C 87.444 60.221 89.712 56.466 97.44 56.448 C 102.815 56.437 105.823 58.474 106.382 63.036 L 106.382 50.88 L 107.596 50.88 L 107.596 87.17 L 118.884 87.17 L 118.884 88.383 L 107.596 88.383 L 107.596 94.635 L 106.382 94.635 Z M 100.96 87.17 L 106.382 87.17 L 106.382 81.56 C 105.664 84.921 103.505 86.471 100.96 87.17 Z M 106.382 65.538 L 100.255 65.538 C 100.259 63.336 99.705 60.975 97.146 60.975 C 95.086 60.975 93.867 62.105 93.867 64.197 C 93.867 69.459 104.589 69.481 106.382 76.759 Z M 98.523 121.845 L 111.908 121.845 L 111.908 127.911 L 108.039 127.911 L 108.039 149.035 L 102.441 149.035 L 102.443 127.9 L 98.523 127.9 Z M 143.107 116.204 L 148.63 116.204 L 140.09 149.035 L 133.532 149.035 L 128.677 129.08 L 134.265 129.08 L 136.903 141.629 L 136.979 141.629 Z M 119.225 127.911 L 113.099 127.911 L 113.099 121.85 L 119.225 121.85 Z M 127.472 127.911 L 121.344 127.911 L 121.344 121.85 L 127.472 121.85 Z M 121.353 129.102 L 127.477 129.102 L 127.466 149.031 L 117.361 149.031 C 117.334 149.031 117.305 149.028 117.276 149.028 C 114.961 149.028 113.096 147.135 113.096 144.791 C 113.096 144.736 113.092 144.686 113.096 144.633 C 113.084 138.314 113.096 129.102 113.096 129.102 L 119.235 129.102 L 119.181 142.102 C 119.181 142.102 119.181 142.128 119.185 142.165 C 119.185 142.176 119.181 142.188 119.181 142.206 C 119.181 142.528 119.339 142.811 119.584 142.98 C 119.617 143.006 119.658 143.024 119.7 143.047 C 119.73 143.06 119.759 143.073 119.793 143.082 C 119.831 143.097 119.868 143.113 119.913 143.124 C 119.973 143.137 120.042 143.143 120.108 143.143 C 120.118 143.143 120.125 143.143 120.138 143.138 C 120.164 143.138 120.185 143.149 120.211 143.146 C 120.266 143.143 121.353 143.146 121.353 143.146 Z M 105.023 160.856 C 102.659 160.856 102.218 159.465 102.318 157.888 L 104.229 157.888 C 104.229 158.757 104.263 159.49 105.314 159.49 C 105.958 159.49 106.275 159.075 106.275 158.456 C 106.275 156.809 102.432 156.711 102.432 153.995 C 102.432 152.566 103.116 151.426 105.44 151.426 C 107.298 151.426 108.222 152.262 108.094 154.172 L 106.239 154.172 C 106.239 153.489 106.124 152.792 105.35 152.792 C 104.733 152.792 104.366 153.134 104.366 153.766 C 104.366 155.498 108.208 155.346 108.208 158.214 C 108.208 160.58 106.477 160.856 105.023 160.856 Z M 112.192 160.706 L 114.718 151.579 L 117.235 151.579 L 119.711 160.706 L 117.701 160.706 L 117.196 158.681 L 114.592 158.681 L 114.074 160.706 Z M 115.87 153.338 L 115.844 153.338 L 114.972 157.281 L 116.791 157.281 Z M 122.884 160.706 L 125.415 151.579 L 127.931 151.579 L 130.406 160.706 L 128.398 160.706 L 127.892 158.681 L 125.29 158.681 L 124.769 160.706 Z M 126.564 153.338 L 126.54 153.338 L 125.666 157.281 L 127.486 157.281 Z M 136.331 160.706 L 134.421 160.706 L 134.421 151.579 L 137.946 151.579 C 139.248 151.579 140.082 152.412 140.082 153.969 C 140.082 155.131 139.627 156.006 138.389 156.207 L 138.389 156.23 C 138.806 156.282 140.045 156.382 140.045 158.026 C 140.045 158.609 140.082 160.326 140.259 160.706 L 138.389 160.706 C 138.137 160.15 138.186 159.53 138.186 158.936 C 138.186 157.847 138.289 156.926 136.823 156.926 L 136.331 156.926 Z M 136.331 155.522 L 137.175 155.522 C 137.934 155.522 138.148 154.765 138.148 154.184 C 138.148 153.311 137.782 152.983 137.175 152.983 L 136.331 152.983 Z M 149.492 112.121 L 134.543 112.121 L 134.543 74.747 C 134.543 41.721 107.771 14.946 74.744 14.946 C 41.72 14.946 14.948 41.721 14.948 74.747 C 14.948 74.798 0 74.798 0 74.747 C 0 33.466 33.463 0 74.744 0 C 116.027 0 149.492 33.465 149.492 74.747 Z M 29.198 27.444 L 28.472 28.115 C 28.963 28.68 30.162 29.981 31.847 28.396 C 32.797 27.519 33.274 26.354 32.157 25.141 C 30.473 23.313 28.056 25.884 26.887 24.615 C 26.313 23.993 26.554 23.357 26.993 22.952 C 27.687 22.31 28.269 22.541 28.842 23.179 L 29.608 22.471 C 28.575 21.254 27.514 21.289 26.46 22.261 C 25.495 23.153 25.269 24.367 26.21 25.388 C 27.806 27.12 30.259 24.588 31.436 25.865 C 32.068 26.551 31.85 27.212 31.267 27.75 C 30.796 28.185 30.073 28.394 29.353 27.612 Z M 70.467 11.697 L 74.568 11.542 L 74.535 10.673 L 71.432 10.792 L 71.329 8.079 L 74.15 7.972 L 74.117 7.104 L 71.296 7.211 L 71.201 4.694 L 74.238 4.579 L 74.206 3.711 L 70.17 3.864 Z M 32.611 17.399 L 33.658 21.372 L 30.136 19.295 L 29.249 19.976 L 33.874 22.547 L 35.691 24.919 L 36.484 24.311 L 34.668 21.94 L 33.413 16.784 Z M 95.445 14.942 L 97.902 7.495 L 96.953 7.182 L 94.497 14.629 Z M 115.573 16.3 L 111.251 13.542 L 110.784 14.275 L 112.524 15.385 L 108.772 21.263 L 109.614 21.8 L 113.366 15.922 L 115.105 17.033 Z M 89.75 13.29 L 90.716 13.545 L 91.628 10.081 L 94.273 10.78 L 94.494 9.941 L 91.849 9.241 L 92.489 6.805 L 95.281 7.544 L 95.503 6.704 L 91.744 5.71 Z M 88.083 12.937 L 89.626 5.247 L 88.646 5.05 L 87.104 12.74 Z M 48.74 17.06 L 52.542 15.497 L 52.211 14.693 L 49.335 15.876 L 48.301 13.366 L 50.915 12.291 L 50.585 11.487 L 47.97 12.563 L 47.011 10.234 L 49.826 9.076 L 49.496 8.273 L 45.755 9.811 Z M 128.765 28.145 L 128.159 27.493 L 123.246 32.067 L 123.231 32.051 L 126.064 25.243 L 125.102 24.21 L 119.363 29.553 L 119.969 30.205 L 124.946 25.572 L 124.96 25.588 L 122.093 32.486 L 123.026 33.488 Z M 112.997 24.162 L 117.646 17.849 L 116.84 17.257 L 112.191 23.569 Z M 116.271 23.008 C 114.855 24.656 114.905 25.831 116.166 26.915 C 117.426 27.998 118.595 27.871 120.011 26.223 L 121.69 24.27 C 122.709 23.084 122.75 21.801 121.49 20.718 C 120.229 19.635 118.968 19.869 117.949 21.056 Z M 119.209 25.59 C 118.09 26.892 117.428 26.896 116.711 26.28 C 115.995 25.664 115.898 25.009 117.017 23.707 L 118.745 21.696 C 119.813 20.452 120.706 21.148 120.945 21.353 C 121.184 21.558 122.005 22.336 120.936 23.58 Z M 67.293 6.287 L 68.316 6.157 C 68.223 4.637 67.53 3.915 65.99 4.109 C 64.46 4.302 63.569 5.049 63.846 7.246 L 64.124 9.444 C 64.504 12.461 65.999 12.338 66.968 12.215 C 67.474 12.151 69.209 11.933 68.856 9.482 L 67.833 9.611 C 68.013 11.131 67.111 11.355 66.81 11.393 C 66.045 11.489 65.392 11.341 65.151 9.435 L 64.889 7.356 C 64.721 6.02 64.89 5.801 64.912 5.711 C 64.93 5.599 65.191 5.063 66.01 4.96 C 66.214 4.934 66.689 4.962 66.924 5.184 C 67.16 5.406 67.248 5.843 67.293 6.287 Z M 102.472 11.546 L 103.427 11.936 C 104.092 10.565 103.843 9.595 102.405 9.008 C 100.977 8.425 99.834 8.639 98.996 10.691 L 98.159 12.742 C 97.01 15.557 98.373 16.184 99.278 16.553 C 99.751 16.746 101.37 17.407 102.265 15.098 L 101.31 14.708 C 100.721 16.122 99.825 15.874 99.544 15.758 C 98.83 15.467 98.333 15.018 99.06 13.238 L 99.852 11.297 C 100.361 10.05 100.616 9.944 100.679 9.875 C 100.75 9.787 101.241 9.447 102.004 9.759 C 102.196 9.838 102.595 10.094 102.692 10.404 C 102.789 10.713 102.651 11.138 102.472 11.546 Z M 54.573 14.769 L 52.663 8.069 L 52.684 8.062 L 56.664 14.174 L 57.573 13.915 L 57.774 6.613 L 57.795 6.607 L 59.706 13.308 L 60.667 13.034 L 58.519 5.499 L 56.93 5.951 L 56.81 12.823 L 56.789 12.829 L 53.084 7.046 L 51.526 7.489 L 53.674 15.025 Z M 107.843 11.711 L 101.977 17.477 L 102.87 17.949 L 104.261 16.573 L 106.939 17.99 L 106.565 19.905 L 107.553 20.429 L 108.966 12.305 Z M 107.949 12.811 L 107.106 17.096 L 104.889 15.922 L 107.929 12.801 Z M 76.957 7.995 L 78.129 8.051 C 78.466 8.067 79.233 8.147 79.264 9.106 C 79.301 10.151 79.187 11.168 79.443 11.724 L 80.484 11.774 C 80.356 11.278 80.307 10.047 80.312 9.71 C 80.332 8.134 80.022 7.815 79.128 7.631 L 79.129 7.61 C 80.059 7.491 80.603 6.81 80.647 5.888 C 80.693 4.911 80.252 3.912 78.863 3.845 L 76.161 3.716 L 75.787 11.549 L 76.785 11.597 Z M 76.999 7.127 L 77.118 4.631 L 78.626 4.704 C 79.397 4.74 79.648 5.383 79.621 5.947 C 79.589 6.631 79.212 7.233 78.496 7.198 Z M 87.124 4.733 L 82.039 4.048 L 81.924 4.909 L 83.971 5.185 L 83.04 12.091 L 84.03 12.224 L 84.961 5.318 L 87.008 5.593 Z M 44.294 10.453 L 39.734 12.794 L 40.131 13.567 L 41.966 12.625 L 45.15 18.825 L 46.039 18.369 L 42.855 12.168 L 44.69 11.226 Z M 38.317 20.142 L 37.481 20.671 C 37.863 21.316 38.808 22.811 40.753 21.554 C 41.846 20.862 42.526 19.802 41.645 18.408 C 40.317 16.308 37.475 18.403 36.553 16.945 C 36.1 16.23 36.452 15.647 36.958 15.327 C 37.757 14.821 38.288 15.153 38.737 15.883 L 39.619 15.325 C 38.821 13.942 37.771 13.786 36.558 14.553 C 35.446 15.256 35.005 16.409 35.747 17.583 C 37.005 19.573 39.877 17.525 40.805 18.991 C 41.304 19.78 40.969 20.39 40.298 20.815 C 39.756 21.157 39.007 21.234 38.439 20.335 Z M 0.394 83.056 L 0.247 81.609 L 11.605 80.452 L 11.752 81.899 Z M 4.384 87.154 L 4.059 87.218 C 2.538 87.516 2.245 88.572 2.424 89.487 C 2.646 90.62 3.297 91.396 4.631 91.134 C 7.114 90.649 5.851 85.675 9.219 85.017 C 11.205 84.628 12.537 85.833 12.904 87.711 C 13.305 89.759 12.536 91.102 10.237 91.455 L 9.945 89.966 C 11.174 89.741 11.905 89.195 11.641 87.845 C 11.474 86.991 10.87 86.208 9.659 86.444 C 7.192 86.928 8.533 91.886 4.979 92.581 C 2.62 93.042 1.541 91.562 1.18 89.715 C 0.502 86.416 3.031 85.921 4.108 85.742 Z M 6.887 95.067 L 10.449 93.903 C 12.614 93.195 14.36 93.856 15.112 96.155 C 15.863 98.455 14.844 100.018 12.68 100.726 L 9.118 101.89 C 6.112 102.874 4.561 102.149 3.809 99.85 C 3.058 97.551 3.881 96.05 6.887 95.067 Z M 8.596 100.498 L 12.263 99.299 C 14.533 98.557 14.097 96.97 13.955 96.533 C 13.812 96.098 13.226 94.559 10.956 95.301 L 7.289 96.5 C 4.914 97.276 4.539 98.164 4.967 99.472 C 5.394 100.779 6.221 101.274 8.596 100.498 Z M 8.033 109.829 L 9.149 109.233 C 14.621 109.949 15.793 110.399 17.467 109.506 C 18.234 109.095 18.549 108.444 18.109 107.621 C 17.596 106.659 16.704 106.902 15.93 107.333 L 15.231 106.022 C 16.775 105.053 18.252 105.304 19.131 106.95 C 20.062 108.693 19.714 109.955 17.971 110.885 C 15.809 112.04 14.503 111.339 9.878 110.599 L 11.926 114.435 L 10.811 115.031 Z M 21.044 110.762 L 24.287 115.423 L 23.248 116.146 L 13.604 119.291 L 12.665 117.94 L 22.39 114.913 L 20.005 111.485 Z M 25.051 124.728 C 22.921 126.641 20.838 128.536 18.85 126.324 C 16.862 124.112 18.966 122.242 21.096 120.328 C 23.296 118.35 25.311 116.475 27.32 118.711 C 29.329 120.946 27.251 122.751 25.051 124.728 Z M 21.857 121.6 C 20.481 122.838 18.677 124.31 19.756 125.509 C 20.834 126.71 22.49 125.073 23.866 123.836 C 26.066 121.858 27.408 120.631 26.415 119.525 C 25.42 118.419 24.057 119.623 21.857 121.6 Z M 30.863 129.914 C 28.991 132.079 27.161 134.218 24.912 132.274 C 22.663 130.329 24.517 128.21 26.389 126.045 C 28.324 123.807 30.088 121.695 32.361 123.661 C 34.634 125.627 32.798 127.676 30.863 129.914 Z M 27.304 127.212 C 26.093 128.611 24.489 130.298 25.709 131.353 C 26.929 132.408 28.366 130.577 29.577 129.177 C 31.511 126.94 32.689 125.554 31.565 124.582 C 30.44 123.609 29.238 124.974 27.304 127.212 Z M 32.69 137.814 L 31.48 137.006 L 36.691 129.206 L 34.708 129.214 L 35.481 128.055 C 35.872 128.126 37.18 128.048 37.75 127.992 L 38.789 128.686 Z" fill="rgb(255, 255, 255)" height="160.85599487304688px" id="W0jOBdy1B" width="149.49200000000002px"/></g></svg>)




